Build 2015: Microsoft Launches Azure Data Lake

Big Data repository for analytics on Microsoft Azure has been announced at Build 2015
Microsoft has announced its version of a data lake at this year’s Microsoft Build conference, allowing Azure customers to now take advantage and analyse large chunks of big data for their business.
A data lake is a repository of Big Data that adheres to no set requirements of size or definitions, ie, it’s a massive lake of every piece of data including the kitchen sink.
Every type of data
As Oliver Chiu, product marketing for Hadoop and Big Data at Microsoft puts it: “In the industry, the concept of a data lake is relatively new. It’s as an enterprise wide repository of every type of data collected in a single place prior to any formal definition of requirements or schema. This allows every type of data to be kept without discrimination regardless of its size, structure, or how fast it is ingested.”
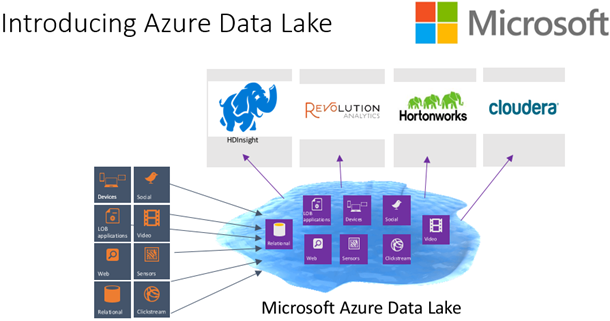
Microsoft intends for users to Hadoop or advanced analytics to then find patterns in the data in the data lake. Chiu also points out that a data lake can also be utilised as a repository for lower cost data preparation, before it is moved into a data warehouse.
 The Azure Data Lake is a Hadoop File System compatible with HDFS, enabling Microsoft services such as Azure HDInsight, Revolution-R Enterprise, industry Hadoop distributions like Hortonworks and Cloudera all to connect to it.
The Azure Data Lake is a Hadoop File System compatible with HDFS, enabling Microsoft services such as Azure HDInsight, Revolution-R Enterprise, industry Hadoop distributions like Hortonworks and Cloudera all to connect to it.
Chiu said: “The goal of the data lake is to run Hadoop and advanced analytics on all your data to discover conclusions from the data itself.
“Azure Data Lake meets this requirement with no fixed limits to how much data can be stored in a single account. It can also store very large files with no fixed limits to size. It is built to handle high volumes of small writes at low latency making it optimized for near real-time scenarios like website analytics, Internet of Things (IoT), analytics from sensors, and others.”
Take our Microsoft executives quiz here!





